Qu'est-ce qu'une facette ?
Une facette est un moyen de filtrer sur une collection de données. Elle agit en complément de la requête, en se basant sur celle-ci.
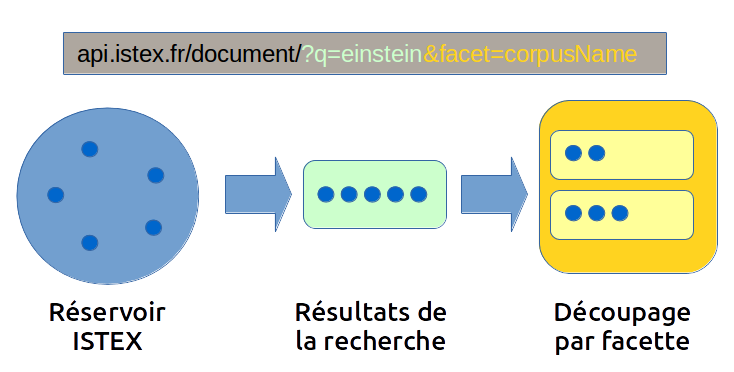
Un exemple est toujours plus parlant
Reprenons le schéma ci-dessus. Nous souhaitons connaître tous les documents de la base ISTEX comprenant le mot "einstein". Nous avons donc effectué une requête ?q=einstein, ce qui correspond à la première partie du schéma :
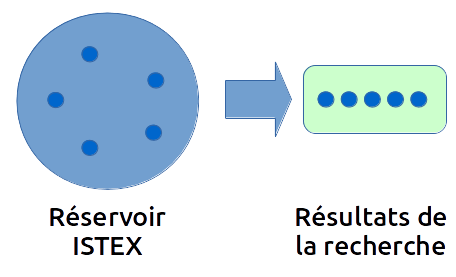
Ici, la recherche ne nous a retourné que 5 résultats, représentés par les points bleus (il s'agit évidemment d'un exemple). Nous souhaitons maintenant, en plus, connaître quels sont les corpus concernés, et combien de documents sont affectés à ces corpus. Il existe alors plusieurs solutions :
- Nous pouvons, par exemple, effectuer plusieurs requêtes en ajoutant à la recherche précédente les noms des corpus, par exemple ?q=einstein AND corpusName:elsevier, puis ?q=einstein AND corpusName:wiley, etc. Non seulement faire cet ensemble de requête est fastidieux, mais le risque d'oublier un corpus est important.
- Nous pouvons également utiliser l'option &output=corpusName pour afficher le champ concerné, et compter manuellement le nombre de fois où chaque nom de corpus apparait. Dans notre exemple, avec 5 résultats, cela peut sembler simple, mais la majorité des requêtes propose un nombre de résultats bien plus important.
La meilleure solution consiste alors à utiliser une facette &facet=corpusName. Cette dernière va, en plus du résultat de la requête, ajouter un objet "aggregations" à la fin du JSON généré. Cet objet montre le découpage des 5 résultats trouvés par leur nom de corpus :
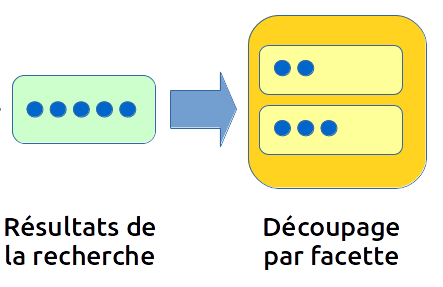
Ici, nous n'avons que deux noms de corpus (par exemple, elsevier et wiley), le premier contenant 2 des résultats et le second les 3 autres.
Les facettes sont donc très utiles pour filtrer sur une collection de données. Elles permettent, comme ici, de générer des états de collection, mais également à montrer à l'utilisateur final des moyens d'affiner leur recherche. En effet, l'objet "aggregations" peut être mappé sur votre portail :
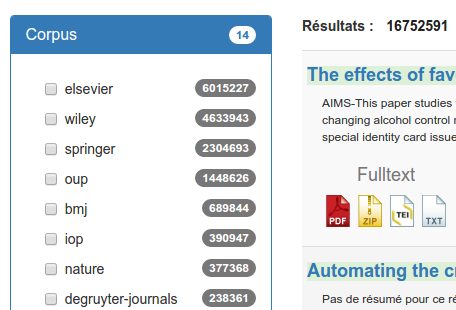
Ainsi, l'utilisateur pourra choisir quels critères ajouter à sa recherche plus facilement.
Syntaxe
| Syntaxe |
|------------ | ------------- |
| URI | https://api.istex.fr/document/?q={query}&facet={liste des champs} |
| Explications | Cette option permet de sélectionner une ou des facettes basées sur les champs disponibles.
La liste des champs est séparée par des , (virgules).
Attention, les facettes ignorent les résultats qui ne possèdent pas le champ demandé. Par exemple, une facette sur
le champ "copyrightDate" ne prendra pas en compte les résultats de la requête sans "copyrightDate" renseignée.
La liste des facettes souhaitées peut être renseignée de deux manières :
- en utilisant le nom du champ selon le mapping,
- en utilisant les alias fournis
La liste des options disponibles diffère selon le type du champ interrogé.|
| Paramètres | - &facet : l'option permettant de définir les facettes à effectuer,
- {liste des champs} : la liste en question, séparée par des virgules. |
| Code de retour | - 200 si OK,
- 500 en cas de problème (dans ce cas, contacter api-bug@listes.istex.fr) |
Facettes dynamiques selon le mapping
L'API permet d'utiliser des facettes "à la volée", en se basant sur les champs disponibles : ici. Il s'agit de la manière classique d'utilisation des facettes.
Les niveaux d'arborescence d'un champ sont ici représentés par des . (points). Par exemple, pour avoir le numéro de la première page présente dans le host, on utilisera le champ host.pages.first.
Champs de type string et boolean
| Informations |
|------------ | ------------- |
| Options | - x : renvoie les 10 termes du champ x les plus présents dans les résultats de la requête,
- x[y] : renvoie les y termes du champ x les plus présents dans les résultats de la requête,
- x[*] : renvoie tous les termes du champ x présents dans les résultats de la requête, dans la limite de 1000 termes maximum. |
| Détails | Les résultats sont affichés du terme le plus présent vers le terme le plus rare.
Attention, certains champs ne peuvent être interrogés, leur résultat étant jugé non pertinent
et trop conséquent pour être affiché : doi, title, abstract|
| Format de réponse |
{ "aggregations": {
"corpusName": {
"docCountErrorUpperBound": 0,
"sumOtherDocCount": 0,
"keyCount": 2,
"buckets": [
{
"key": "elsevier",
"docCount": 1230
},
{
"key": "wiley",
"docCount": 577
}
]
}
}
}- sumOtherDocCount : somme des documents avec des termes supplémentaires non affichés ici,
- keyCount : nombre de termes différents affiché,
- buckets : tableau contenant l'état de collection,
- key : terme trouvé,
- docCount : nombre de fois où ce terme a été trouvé. |
| Exemples |
| -------- | ------- |
| Affichage de l'ensemble des documents avec une facette sur les 10 corpus les plus présents | https://api.istex.fr/document/?q=&facet=corpusName
https://api.istex.fr/document/?q=*&facet=corpusName[10] |
| Affichage de l'ensemble des documents avec une facette sur tous les corpus présents | https://api.istex.fr/document/?q=*&facet=corpusName[*]|
| Affichage de l'ensemble des documents avec une facette sur les 5 corpus les plus présents | https://api.istex.fr/document/?q=&facet=corpusName[5]|
Champs de type integer et double
| Informations |
|------------ | ------------- |
| Options | - x : renvoie le nombre de résultats ayant un chiffre pour le champ x compris entre le chiffre le plus bas et le plus haut,
- x[y-z] : renvoie le nombre de résultats ayant un chiffre pour le champ x compris entre y et z,
- x[y-z:i] : renvoie le nombre de résultats par intervalle i ayant un chiffre pour le champ x compris entre y et z.
Les valeurs y et z peuvent prendre comme valeur * (étoile) pour désigner les valeurs minimale et maximale. |
| Format de réponse pour une facette x[y-z]|
{
"aggregations": {
"qualityIndicators.score": {
"buckets": [
{
"key": "0.013-9.5",
"from": 0.013,
"fromAsString": "0.013",
"to": 9.5,
"toAsString": "9.5",
"docCount": 2303789
}
]
}
}
}- key : correspond à "y - z" (string),
- from : correspond à y (numérique),
- fromAsString : correspond à y (string),
- to : correspond à z (numérique),
- toAsString : correspond à z (string),
- docCount : nombre de résultats trouvé. | | Format de réponse pour une facette x[y-z:i]|
{
"aggregations": {
"qualityIndicators.score": {
"docCount": 9119,
"buckets": [
{
"key": 0,
"rangeAsString": "[0-2[",
"docCount": 2996
},
{
"key": 2,
"rangeAsString": "[2-4[",
"docCount": 1400
},
...
]
}
}
}Les résultats sont découpés selon l'intervalle choisi.
Prenons un exemple : un intervalle de 2 entre 0 et 5 créera 3 résultats :
- le nombre de documents entre 0 et 2 non inclu,
- le nombre de documents entre 2 et 4 non inclu,
- le nombre de documents entre 4 et 5 inclu.
Mathématiquement, on aura : [0-5:2] = [0-2[ + [2-4[ + [4-5]
La facette affiche ces intervalles en indiquant la borne inférieure comme référence (key).
- docCount : nombre de documents concerné par l'intervalle [x-y] de la facette,
- buckets : tableau contenant l'état de collection,
- key : correspond à la borne inférieure de l'intervalle créé (number),
- rangeAsString : correspond à la notation mathématique de l'intervalle créé (string),
- docCount : nombre de résultats trouvé dans l'intervalle. |
| Exemples |
| -------- | ------- |
| Affichage de l'ensemble des documents avec une facette sur l'ensemble des scores de qualité | https://api.istex.fr/document/?q=*&facet=qualityIndicators.score
https://api.istex.fr/document/?q=&facet=score|
| Affichage de l'ensemble des documents avec une facette sur les scores de qualité compris entre 5 et 7 | https://api.istex.fr/document/?q=*&facet=qualityIndicators.score[5-7]
https://api.istex.fr/document/?q=&facet=score[5-7]|
| Affichage de l'ensemble des documents avec une facette sur les scores de qualité compris entre 5 et 7 par intervalle de 1 | https://api.istex.fr/document/?q=*&facet=qualityIndicators.score[5-7:1]
https://api.istex.fr/document/?q=*&facet=score[5-7:1]|
Champs de type date
| Informations |
|------------ | ------------- |
| Options | - x : renvoie le nombre de résultats ayant une date pour le champ x compris entre la date la plus ancienne et la plus récente,
- x[y-z] : renvoie le nombre de résultats ayant une date pour le champ x compris entre y et z,
- x[y-z:i] : renvoie le nombre de résultats ayant une date pour le champ x entre l'année y et z, affiché par intervalle de i années,
- x[perYear] : équivalent à [*-*:1], renvoie le nombre de résultats ayant une date pour le champ x, affiché par année.
Les valeurs y et z peuvent prendre comme valeur * (étoile) pour désigner les valeurs minimale et maximale. |
| Détails | Les résultats sont affichés du terme le plus présent vers le terme le plus rare.
Attention, certains champs ne peuvent être interrogés, leur résultat étant jugé non pertinent
et trop conséquent pour être affiché : doi, title, abstract|
| Format de réponse pour une facette x[y-z] |
{
"aggregations": {
"publicationDate": {
"buckets": [
{
"key": "1836-1972",
"from": -4228675200000,
"fromAsString": "1836",
"to": 63072000000,
"toAsString": "1972",
"docCount": 581
}
]
}
}
}- key : correspond à "y - z" (string),
- from : correspond à y (timestamp en millisecondes),
- fromAsString : correspond à y (string),
- to : correspond à z (timestamp en millisecondes),
- toAsString : correspond à z (string),
- docCount : nombre de résultats trouvé dans cet intervalle. | | Format de réponse pour une facette x[y-z:i]|
{
"aggregations": {
"copyrightDate": {
"buckets": [
{
"keyAsString": "1832",
"key": -4354905600000,
"docCount": 50,
"rangeAsString": "[1832-1833["
},
{
"keyAsString": "1833",
"key": -4323283200000,
"docCount": 62,
"rangeAsString": "[1833-1834["
},
...
}
}
}
}Il n'est pas possible également de continuer avec une facette imbriquée : les facettes suivantes seront supprimées.
Les résultats sont découpés selon l'intervalle choisi.
Prenons un exemple : un intervalle de 2 entre 2000 et 2004 créera 3 résultats :
- le nombre de documents entre 2000 et 2002 non inclu,
- le nombre de documents entre 2002 et 2004 non inclu,
- le nombre de documents en 2004.
Mathématiquement, on aura : [2000-2004:2] = [2000-2002[ + [2002-2004[ + [2004-2004]
La facette affiche ces intervalles en indiquant la borne inférieure comme référence (key et keyAsString).
La facette affiche les dates de la plus ancienne à la plus récente.
- buckets : tableau contenant l'état de collection,
- keyAsString : année trouvée (année en string),
- key : année trouvée (timestamp en millisecondes),
- docCount : nombre de résultats trouvé pour cette année,
- rangeAsString : correspond à la notation mathématique de l'intervalle créé (string). |
| Exemples |
| -------- | ------- |
| Affichage de l'ensemble des documents avec une facette sur l'ensemble des dates de publication | https://api.istex.fr/document/?q=&facet=publicationDate|
| Affichage de l'ensemble des documents avec une facette sur les dates de publication compris entre 1900 et 2000 | https://api.istex.fr/document/?q=&facet=publicationDate[1900-2000]|
| Affichage de l'ensemble des documents avec une facette sur l'ensemble des dates de publication, découpé par année | https://api.istex.fr/document/?q=*&facet=publicationDate[perYear]
https://api.istex.fr/document/?q=*&facet=publicationDate[*-*:1]
https://api.istex.fr/document/?q=*&facet=publicationDateOverTime|